在百度、阿里、360、商汤等国内企业纷纷宣布入局AI大模型之后,面向大模型训练的高性能计算需求也迎来井喷式增长。
4月14日,腾讯云正式发布新一代HCC(High-Performance Computing Cluster)高性能计算集群。该集群采用腾讯云星星海自研服务器,搭载英伟达最新代次H800 GPU,服务器之间采用业界最高的3.2T超高互联带宽,为大模型训练、自动驾驶、科学计算等提供高性能、高带宽和低延迟的集群算力。实测显示,腾讯云新一代集群的算力性能较前代提升高达3倍,是当前国内性能最强的大模型计算集群。
2022年10月,腾讯完成首个万亿参数的AI大模型——混元NLP大模型训练。在同等数据集下,将训练时间由50天缩短到11天。如果基于新一代集群,训练时间将进一步缩短至4天。
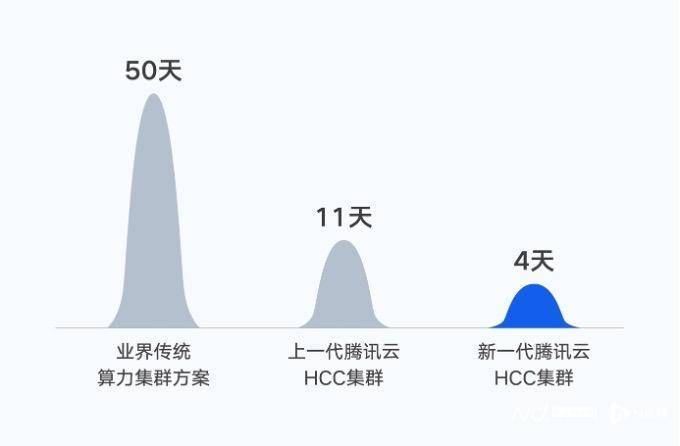
大模型进入万亿参数时代,单体服务器算力有限,需要将大量服务器通过高性能网络相连,打造大规模算力集群。通过对处理器、网络架构和存储性能的全面优化,腾讯云宣布攻克了大集群场景下的算力损耗问题,为大模型训练提供高性能、高带宽、低延迟的智算能力支撑。
据介绍,目前,腾讯混元AI大模型已经覆盖了自然语言处理、计算机视觉、多模态等基础模型和众多行业、领域模型。腾讯混元大模型背后的训练框架AngelPTM,也已通过腾讯云对外提供服务,帮助企业加速大模型落地。
数据、算法和算力是AI大模型的三大要素,其中算力不足也是限制AI大模型发展的瓶颈之一。随着国内企业纷纷开启对通用大模型、垂直行业大模型的训练和应用,对算力的需求也迎来井喷式增长,如何通过算力优化提升大模型训练效率成为各家竞逐的焦点。
4月11日的阿里云北京峰会上,阿里云披露其高性能AI训练计算平台“灵骏智算”,可以实现800G全速无拥塞RDMA网络,网络通信时延低至2微秒。在此基础之上,灵骏可支持最大十万卡GPU的单集群规模,可以承载多个万亿参数规模的大模型同时在线训练。在高性能网络集群的基础上,阿里巴巴构建了PAI-灵骏产品来提供大数据加AI一体化平台,从而能够高效推动算法的开发迭代,支撑超大规模模型训练任务,为大模型的产生提供系统支持。
腾讯则披露目前,腾讯云的分布式云原生调度总规模超过1.5亿核,并提供16 EFLOPS(每秒1600亿亿次浮点运算)的智算算力。未来,新一代集群不仅能服务于大模型训练,还将在自动驾驶、科学计算、自然语言处理等场景中充分应用。
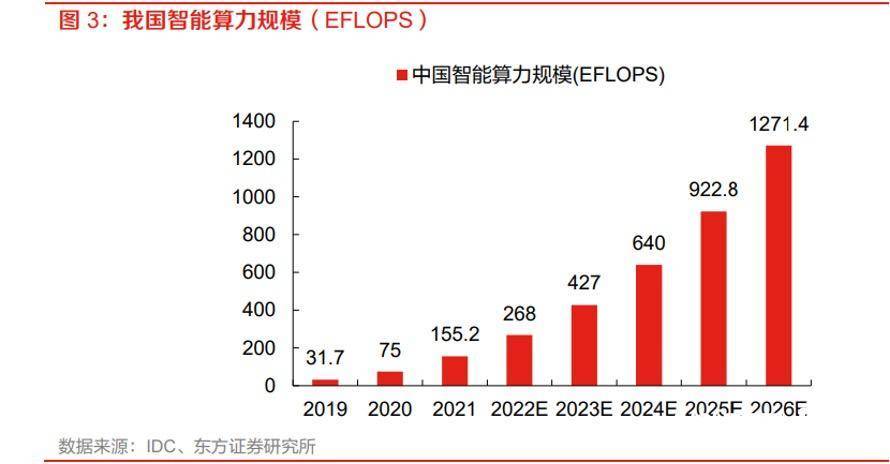
机器学习进入大模型时代,ChatGPT 等通用大模型的训练迭代极大拉动对智能算力的需求。东方证券研报显示,从智能算力总额来看,美、中处于领先地位。从人均智能算力的角度,中国仍处于全球中等水平。 据《中国算力指数发展白皮书(2022)》,美、中的智能算力处于全球领先地位,分别占全球比 重的 45%和 28%。然而从人均算力的高低来衡量,美国、英国、德国等国家的人均算力普遍高 于 1000GFlops,而我国的人均算力处于中等水平。据 IMB 研究发现,人均算力的水平与一国 的智能化水平高度相关,我国积极发展智能算力、打造智算中心是打造国际竞争力、发展综合国力的关键。
采写:南都记者 马宁宁
本文来自投稿,不代表长河网立场,转载请注明出处: http://changhe99.com/a/qErqkXvEdJ.html
